
Lagi Liburan Belajar GPU
Lagi liburan dan gabut seperti biasa. Jadinya scrolling twitter cari hal buat dibaca. Ketemulah twit yang nanya soal cara kerja GPU architecture.
I have some really basic understanding of GPU programming with shaders and CUDA, but am mostly clueless of actual GPU architecture and how code gets executed on it. What books or blog posts would you recommend me to read to catch up?
— Pekka Enberg (@penberg) December 25, 2023
Kebetulan penasaran juga sama cara kerja GPU. Lagi belajar-belajar soal shader karena kena racun suatu former gamedev (ekhem Om didiet ekhem).
Di twit ini ada yang jawab dengan video “How GPU Computing Works”.
Menariknya video nya dari youtube channel per orangan. Semakin yakin ini materi obscure yang biasanya sepuh-sepuh yang ngajarin. Pas diliat pas bener yang ngajar itu engineer dari nvidia. Makin yakin isi video nya daging semua.
Lucunya title “How GPU Computing Works” sama dia dicoret dari “Where’s My Data?”. Gw langsung paham orang ini data driven programmer. Didalam videonya isinya banyak jelasin konsep seperti GPU itu sebenernya punya issue dengan latency dari fetching data dan calculating data.

GPU pun punya latency yang gede dibanding computation powernya. Jadi kalo lakuin kalkulasi, memory bus nya banyak engga aktif karena nunggu latency.

“gpu have far more thread than you need. it’s design for over subscribtions”
Ini quote dari videonya yang menurut gw penting banget. Mental model gw terhadap GPU itu merka punya banyak core tapi engga genral purpose. Tapi gw masih mikir mereka cara kerjanya kayak CPU aja. Tapi GPU ini didesign untuk dikasih task terus, beda dibanding CPU. CPU kalau dikasih task terlalu banyak, cost untuk context switching antara thread itu terlalu mahal. Jadinya konsep di CPU itu punya thread dan memory ratio yang mendekati 1:1.
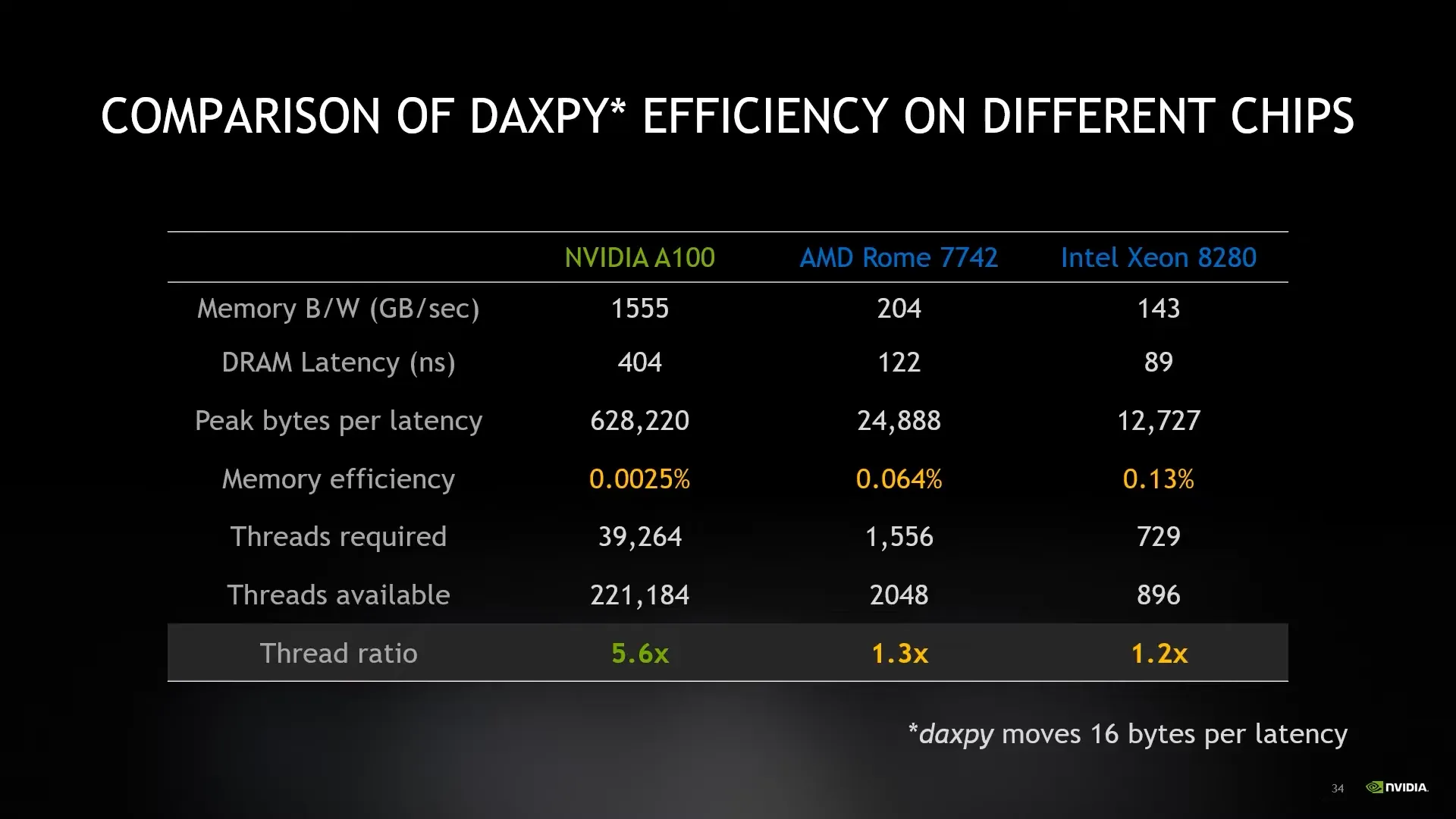
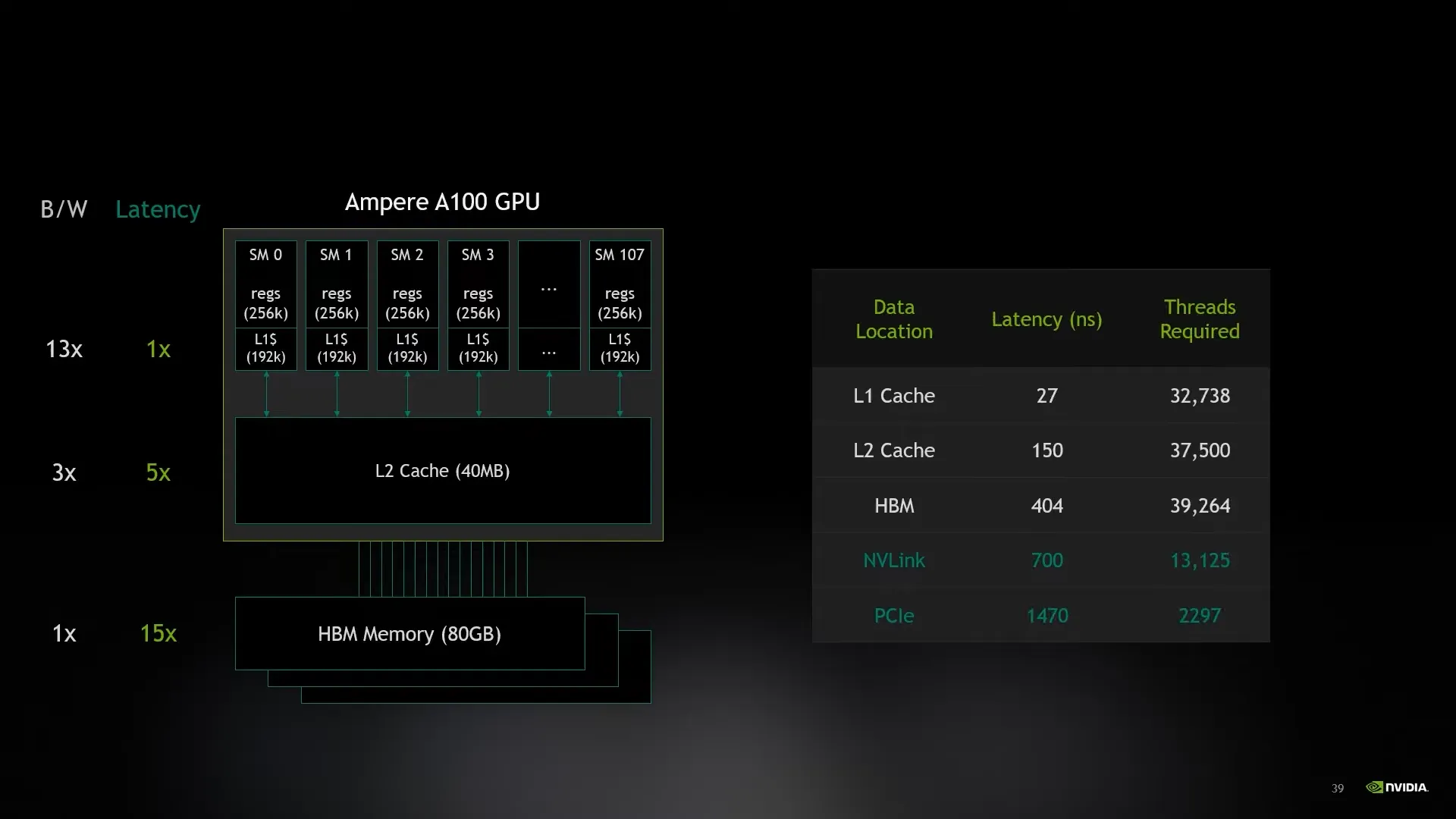
Untuk membuat GPU ini sibuk terus, berarti memorry nya itu perlu selalu dimaksimalkan. Tetapi balik ke issue awal tentang latency. Memory di GPU ini pun punya beberapa tier seperti di CPU. Ada L1 dan l2 cache, VRAM, nvlink (sharing memorry antara 2 GPU di nvidia), dan PCIe (memorry dari RAM). Setiap turun tier nya, latency naik dan bandwidth nya turun. Telihat juga mengambil data dari RAM itu bandwidth nya jadi pelan banget. Alesan utama kenapa pake VRAM dan engga pake RAM yang kirim ke GPU. Ratio antara latency dan thread yang diperluin dari L1, L2, dan VRAM itu mirip. Secara design mereka tidak ada bottleneck dan scale secara natural. Nvlink lebih mendekati dengan ratio VRAM dimana RAM itu latency teralu tinggi.
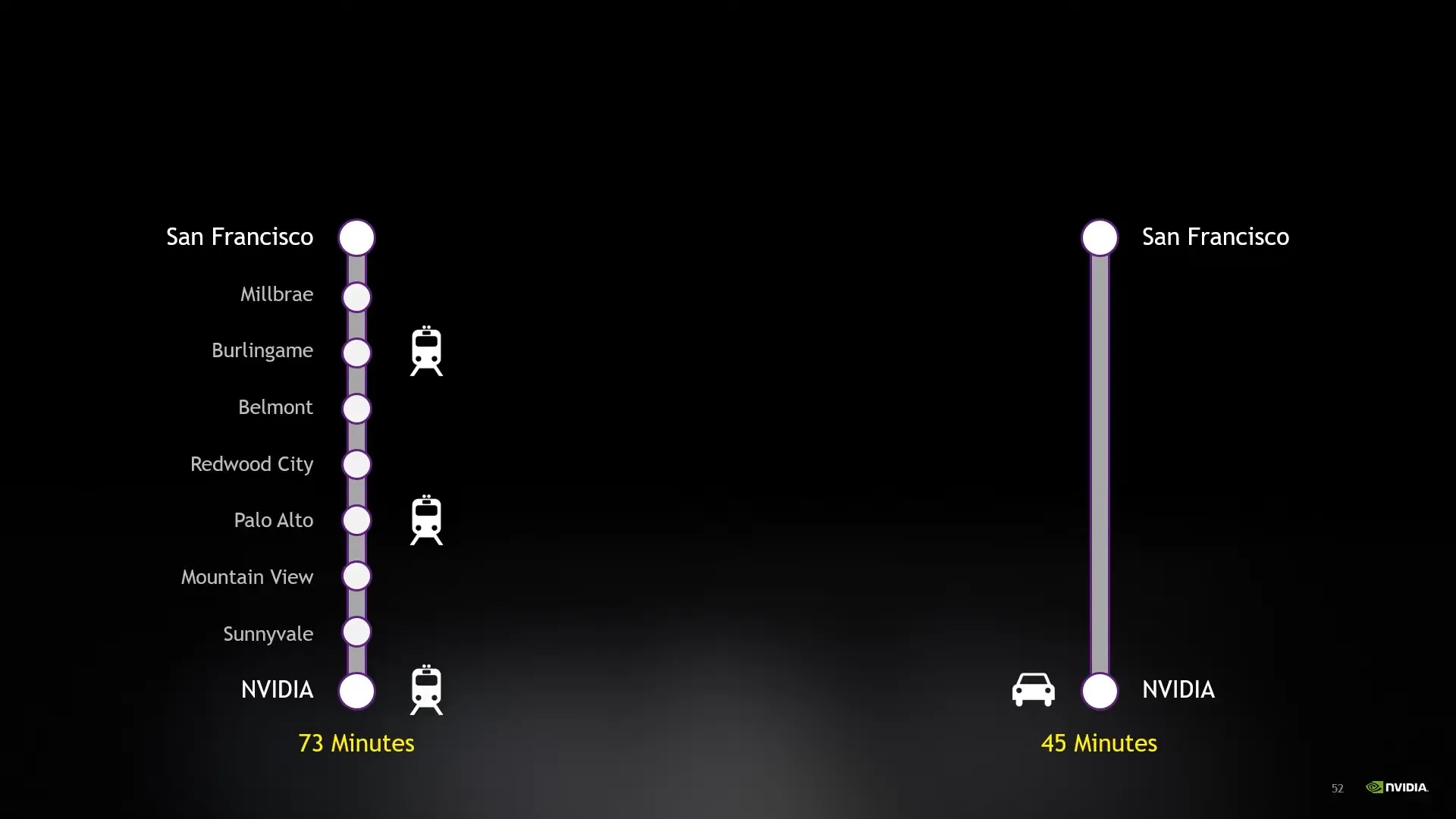
Konsep yang menarik juga yang diajarin itu mengenai throughput vs latency. Ada analogy kereta sama mobil. GPU di anggep kereta dan CPU dianggep mobil. Kalo mobil itu bisa dari titik a ke b lebih cepet dibanding kereta, tapi kereta itu bisa bawa penumpang lebih banyak. Jadi mobil ini latency nya lebih kecil karena bisa lebih cepet, tapi throughput nya lebih kecil karena bawa penumpang nya lebih dikit. Bisa di samain kayak GPU, latency untuk kalkulasi di GPU lebih besar, tapi karena thread nya banyak jadi dalam satu waktu bisa kalkulasi hal lebih banyak.
Video ini ngingetin balik ke gw soal data driven programing. Kita ngoding ini platform nya memang computation hardware. Secara esensi mereka itu diberi data, instruksi cara mengolah data dan mengembalikan data. Sebagai programmer kita fokusnya ke gimana secara efisien bisa memindahkan dan mengolah data ini.